By "natural language", we mean the language that people speak and right, such as English, Spanish, Mandarin, etc. The dominant language of science today is English and that is my research focus. Since my research is on figuring out the content of the scientific literature, I work on both the natural language and diagram content of papers, primarily papers in the biology research literature. Natural language is very different from computer languages, as I discuss below.
The first modern revolution in the understanding of language came in 1957, with the publication of Syntactic Structures by Noam Chomsky (MIT). He approached language from a formal point of view, primarily through the mathematical theory of grammars, which was just starting to develop at the time. Famous as he and his work is, he has unfortunately stuck to that view while the field moved steadily beyond him. The second major revolution came with the advent of computers and especially recently, as computers have become big and fast enough to analyze many millions of words at a shot. But most of this work has still focused on using statistical methods to derive the rules of grammar for further analysis of language syntax and semantics. Now, there is a growing number of researchers, including me, that feel that language is not fundamentally rule-based but instead operates by associative, memory-based strategies. One of the prime proponents of this approach is Walter Daelemans (look him up!). Some of the evidence for the role of memory in language comes from our abilities to memorize words and idioms. An adult typically has a vocabulary approaching 200,000 words. These words are arbitrary associations between a symbol or sound and the word meaning and other properties. People simply have to learn that "bear" can be an animal or a quite different verb, whereas "bean", differing by a single character is quite different. This suggests that people have the ability to memorize language patterns, not just isolated words.
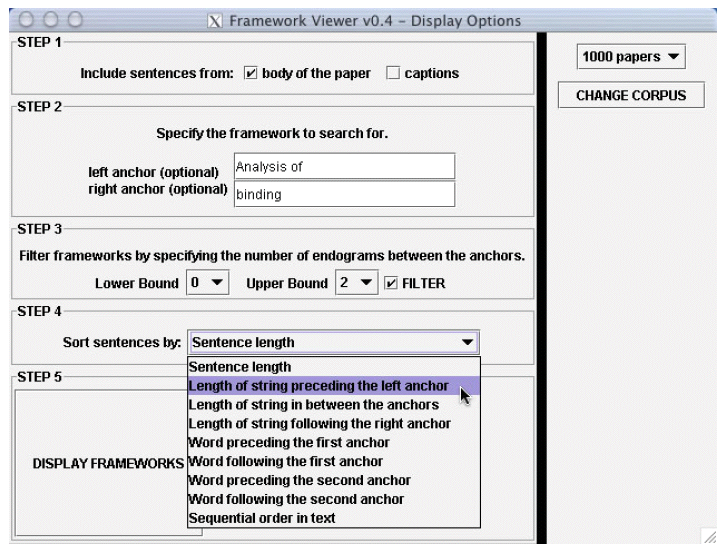
My recent work in this field is based on my familiarity with the biology literature and the realization that biologists use the same phrases, language patterns, over and over. A non-biology example should make this clear: "The high today will be 50 degrees." This is a stock phrase with a single item of information inserted, "50". Biology text is very much this way. To visualize these patterns, Andrea Grimes, a current Honors student in our college, developed a Framework Viewer, shown below. .
Here's a 4 x 3 foot poster in PDF format that you can scroll and zoom on to get a rather complete picture of Andrea's project. She created this poster and presented it at a meeting at Stanford in the Fall of 2003. The exact reference of her work is:
Grimes, A. E., & Futrelle, R. P. (2003). Text pattern visualization for analysis of biology full text and captions. In Computational Systems Bioinformatics. CSB2003 (pp. 648-651). Palo Alto, CA: IEEE Computer Society.
The software technology behind this system is actually rather complex. We began with a large number of biology articles in HTML format downloaded by a webbot we wrote. Shao broke the text up into "tokens" which separated markup from words as well as breaking up hyphenated words. Large serialized Java files were generated from this analysis. Grimes analyzed the documents to locate ads (ignored), figure captions, etc. and the resulting document structure was represented in XML. Sentences were located by an algorithm adapted from the literature and their serial positions in each paper were stored. For each pattern requested in the control panel, the sentences containing the pattern were located. Then computations were done to get the character alignment correct. If a middle portion is to long it is elided with ellipsis marks (...). If the user mouses on the ellipsis marks, the entire missing portion pops up in a box at that location. Java Swing was used to display each portion graphically to allow us complete control over positioning. In addition, the layout was only computed for a few hundred sentences. When the user scrolls too far, additional layout is computed with the result that the user is under the impression that she/he is scrolling through tens of thousands of sentences, where in fact only a bit more than the visible ones are computed at any one time. This is a classic form of "lazy evaluation", the generic CS term for delaying the computation of something until it's actually needed.
The assignments page covers the material from both lectures.
Return to Prof. Futrelle's Sp04 Honors homepage or his Teaching Gateway or homepage
{kind=link}
{kind=link}