Created: Tue 7 Jul 2009
Last modified:
Assigned:
Tue 14 July 2009
Due:
Mon 27 July 2009 (hard deadline)
Building an IR system
In this project you will implement a number of different
ranking functions, i.e. algorithms that given a user's request (query) and a corpus of
documents assign a score to each document according to its relevance to the query. Some
of these ranking functions will be the implementation of the basic retrieval models studied
in the class (e.g. TF-IDF, BM25, Language Models with different Smoothing) while others may be
more complicated (e.g. incorporating PageRank, Metasearch over different basic ranking functions,
Relevance Feedback, Query Expansion, Learning-to-Rank). In any case, we will provide you
with the necessary infrastructure so you can have access to any statistics (such as Term Frequencies,
Document Frequencies, Collection Term Frequencies, etc.) you need, without having to implement the
retrieval system from scratch.
The project is split into three different phases. During the first phase (Phase I) you will
have the chance to get familiar with the interface we provide you to access all necessary statistics (web interface).
This means that you will need (1) to understand the different options provided by the interface, (2) to
access this interface from the language of your choice, (3) read the data from the returned output of the interface,
and (4) store them in the appropriate data structures. During the second phase (Phase II) you will have to implement
a number of basic ranking functions, run a set of queries over the provided document corpus and finally evaluate the
effectiveness of the different ranking functions. Finally, during the third phase you will have to enhance the basic
retrieval models in a number of different ways.
Phase I
This project requires that you construct a search engine that can run queries on a corpus and
return a ranked list of documents. Rather than having you build a system
from the ground up, we are providing a Web interface to an existing search
engine. That interface provides you with access to corpus statistics,
document information, inverted lists, and so on. You can access all the necessary
information via the provided Web interface, thus you can implement your project in
any language that provides you with Web access, and can run it on any computer
that has access to the Web.
Computers in the CCIS department will work just fine, but you are more than welcome
to use your own computer.
One of the nice things about the CGI interface is that you can get an idea of
what it does using any browser. For example, the following CGI
command:
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?v=encryption
will get you a list of the documents that contain the word "encryption". Go
ahead and click on the link to see the output (in a separate window). It
lists the number of times the term occurs in the collection (ctf), the total
number of documents that contain it (df) and then, for each of the documents
containing the term, it lists the documents id, it's length (number of terms), and
the number of times the term occurs in that document.
The format is easy for a human to read and should be easy for you to write a
parser for. However, to make it even simpler, the interface provides a
"program" version of its interface that strips out all of the easy-to-read
stuff and gives you a list of numbers that you have to decipher on your own
(mostly it strips the column headings). Here is a variation of the link
above that does that. Click on it to see the difference.
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?g=p&v=encryption
From class, it should be pretty straightforward to imagine how to create a
system that reads in a query, gets the inverted lists for all words in the
query, and then comes up with a ranked list. You may need other
information, and the interface makes everything accessible (we hope).
There is a help command, too:
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?h=
Play around with the engine to ensure it makes sense.
Two important tips:
First, fiji4.ccs.neu.edu is not accessible via name from all CCIS
internal networks; you may need to use the (local) IP address
10.0.0.176 instead. From outside CCIS, the fiji4.ccs.neu.edu name
should always work.
Second, in order to get efficient processing out of this server, you should
string as many commands together as you can. For example, if you want to
get statistics information for three terms, ask for them all at once as in:
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?v=encryption&v=star&v=retrieval
(If you use the program mode version of the same command Lemur images are dropped.) This is because there is some overhead getting the process started, and putting commands together amortizes that over several requests. It works to do them separately, but it might take longer.
This first phase of the project has neither deliverables nor a due date. However, bearing in mind that in Phase II you will need to implement a number of different ranking functions and thus calculate things like TF-IDF scores, in this first phase of the project you should be able, given a query, to access the CGI via some programming language, ask for all the statistics required in computing scores like TF-IDF, parse the returned result in order to obtain these statistics and finally store all these statistics in the appropriate data structures. You can find a small list of queries you can use to test your code here. These queries need also to be parsed.
Phase II
Document Corpora
We have made available two different document corpora for you to use, WT2g and WT10g.
Both of the corpora contain Web documents, with the former being a 2GB corpus and the
latter being a 10GB corpus. (Here
you can find details about the WT10g corpus, in case you are interested.) Use the former
corpus (the small web collection, WT2g) when testing your algorithms. When you are sure that your
algorithms work, run your final experiments on the latter corpus (the large web collection, WT10g).
For each one of the corpora we have constructed two different indexes, (a) with stemming,
and (b) without stemming. Both indexes contain stopwords. You can use the "d=?" option to see
details about the four different indexes. When stemming was applied, we used the kstem (Korvatz)
stemmer. Below you can see the output of the "d=?" command.
| IndexID | Index Description | Statistics |
|---|
| 0 | WT2G with stemming | terms= 264,011,758 unique_terms=1,406,855 docs= 247,491 |
| 1 | WT2G without stemming | terms= 264,011,758 unique_terms=1,526,926 docs= 247,491 |
| 2 | WT10G with stemming | terms=1,043,996,953 unique_terms=5,437,660 docs=1,692,096 |
| 3 | WT10G without stemming | terms=1,043,996,953 unique_terms=5,757,032 docs=1,692,096 |
To use any particular index, you need to specify the index number before any other option in the URL,
i.e. to use the WT2g with stemming applied, you need to use the "d=0" option before anything else,e.g.
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?d=1&c=friends
Note that, when you are requesting information about a word over a stemmed index, then the information
returned will be about the stemmed index term of the word. Try,
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?d=0&c=friends
and,
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?d=1&c=friends
and check the number of the documents containing the requested word. This number will be
larger for the stemmed index since "friends" is stemmed to "friend" and thus all documents
that contain the word "friend" will be returned, while for the unstemmed one only the
documents that contain the exact word "friends" will be returned. To see the stemmed version of
a word, try
http://fiji4.ccs.neu.edu/~zerg/lemurcgi_IRclass/lemur.cgi?d=0&m=friends
Queries
Here is a set of 50 TREC queries for the WT2G corpus,
and here is a set of 50 TREC queries for the WT10g corpus
with the format querynum. query, i.e. query number, space, query. Documents from
the corresponding corpora have been judged with respect to their relevance to these queries
by NIST assessors (using the depth pooling method).
Ranking Functions
Your assignment is to run the second set of queries against the WT10g collection,
return a ranked list of documents (the top 1000) in a particular format, and then
submit the ranked lists for evaluation.
Implement the following variations of a retrieval system:
- Vector space model, terms weighted by Okapi tf only (see note), inner product
similarity between vectors.
Note: For Okapi tf on documents use
OKAPI TF=tf/(tf + 0.5 + 1.5*doclen/avgdoclen).
On queries, Okapi tf can be computed in the same way, just use the length of
the query instead of doclen.
- Vector space model, terms weighted by Okapi tf (see note) times an IDF value, inner
product similarity between vectors. The database information command (D=database_number)
provides collection-wide statistics that you need.
Note:You will have to use for the weights OKAPI TF x IDF w
here OKAPI TF is same as for system
above.
Also note that in different texts you may find different definitions of the OKAPI TF
formula, e.g. OKAPI-TF = tf / tf + k1((1-b) + b*doclen/avgdoclenlook).
In the formula above you can set k1=2 and b=0.75, to end up with:
tf / (tf + 0.5 + 1.5*doclen/avgdoclen).
- Language modeling,
maximum likelihood estimates with Laplace smoothing only, query
likelihood. The database information command provides collection-wide
statistics that you need.
Note: If you use multinomial model, for every document, only the
probabilities associated with terms in the query must be estimated
because the others are missing from the query-likelihood formula (consult
slides
on pages 13-19).
For model estimation use maximum-likelihood and Laplace smoothing. Use
formula (for term i)
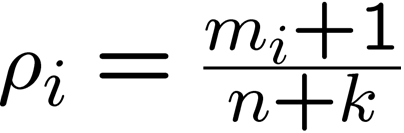
where m = term frequency, n=number of terms in document (doc length) , k=number
of unique terms in corpus.
Language modeling, Jelinek-Mercer smoothing
using the corpus, 0.8 of the weight attached to the background
probability, query likelihood. The database information command
provides collection-wide statistics that you need.
The formula for Jelinek-Mercer smoothing is,
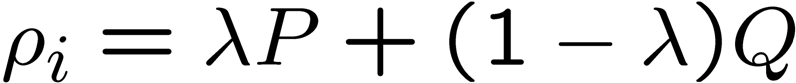
where P is the estimated probability from document (max likelihood = m_i/n) and
Q is the estimated probability from corpus (bkground probab = cf / terms in the
corpus).
Evaluation
Run all 50 queries and return at top 1,000 documents for each query. Do not return
documents with score equal to zero. If there are only N<1000 documents with non-zero
scores then only return these N documents. Save the 50 ranked lists of documents in a single
file. Each file should contain at most 50*1000 = 50,000 lines in it. Each line in the file m
ust have the following format:
query-number Q0 document-id rank score Exp
where query-number is the number of the
query (451 to 500, for the queries over the WT2g corpus and 501 to 550 for the queries over
the WT10g), document-id is the external ID for the retrieved document
(here is a mapping between internal and
external IDs for the WT2g
corpus, and here is a mapping between internal and external IDs for
the WT10g corpus), rank is the rank of the corresponding document in the returned ranked
list (1 is the best and 1000 is the worst; break the ties either arbitrarily or lexicographically),
and score is the score that your ranking function outputs for the document. Scores should
descend while rank increases. "Q0" (Q zero) and "Exp" are constants that are used by some
evaluation software. The overall file should be sorted by ascending rank (so descending
score) within ascending query-number.
Run all four retrieval models against the two WT10g indexes (use the WT2g index just to test your code).
This means you will generate 4 (models) * 2 (indexes) = 8 files, with at most 50,000 lines in total.
To evaluate a single run (i.e. a single file containing 50,000 lines or less), first download the
appropriate qrel file (here you can find the qrel file for the
WT2g corpus, and here you can find the qrel file for the
WT10g corpus. Then, you can download trec_eval
(also see trec_eval_aprp) and run
trec_eval [-q] qrel_file results_file
(The -q option outputs evaluation metrics values for each query; the average
overall queries will be returned is -q is not used).
trec_eval provides a number of statistics about how well the retrieval function
corresponding to the results_file did on the corresponding queries) and includes
average precision, precision at various recall cut-offs, and so on. You will need
some of those statistics for this project's report, and you may find others useful.
(If you have done Problem 5 in HW1 you can use your
own code to output Average Precision and compare it with the output of trec_eval.)
OKAPI TF-IDF on query 401
I ran the okapi tf-idf model on query "401. foreign minorities, germany" for the WT2g collection (with stemming), without doing any fancy query processing (just word tokenization). Below you can find some of the statistics I got back by running trec-eval on the results for this query:
Queryid (Num): 401
Total number of documents over all queries
Retrieved: 1000
Relevant: 45
Rel_ret: 42
Interpolated Recall - Precision Averages:
at 0.00 0.5000
at 0.10 0.3448
at 0.20 0.3448
at 0.30 0.2857
at 0.40 0.2473
at 0.50 0.2473
at 0.60 0.2250
at 0.70 0.2133
at 0.80 0.1622
at 0.90 0.0510
at 1.00 0.0000
Average precision (non-interpolated) for all rel docs(averaged over queries)
0.2165
Precision:
At 5 docs: 0.4000
At 10 docs: 0.2000
At 15 docs: 0.2667
At 20 docs: 0.2500
At 30 docs: 0.3333
At 100 docs: 0.2300
At 200 docs: 0.1750
At 500 docs: 0.0760
At 1000 docs: 0.0420
R-Precision (precision after R (= num_rel for a query) docs retrieved):
Exact: 0.2667
I ran the language model with Laplace smoothing "401. foreign minorities, germany" for the WT2g collection (with stemming), without doing any fancy query processing (just word tokenization). Below you can find some of the statistics I got back by running trec-eval on the results for this query:
Queryid (Num): 401
Total number of documents over all queries
Retrieved: 1000
Relevant: 45
Rel_ret: 36
Interpolated Recall - Precision Averages:
at 0.00 0.8571
at 0.10 0.8571
at 0.20 0.6429
at 0.30 0.5484
at 0.40 0.5294
at 0.50 0.4906
at 0.60 0.4576
at 0.70 0.3137
at 0.80 0.1706
at 0.90 0.0000
at 1.00 0.0000
Average precision (non-interpolated) for all rel docs(averaged over queries)
0.4002
Precision:
At 5 docs: 0.8000
At 10 docs: 0.7000
At 15 docs: 0.6000
At 20 docs: 0.4500
At 30 docs: 0.5333
At 100 docs: 0.3000
At 200 docs: 0.1750
At 500 docs: 0.0720
At 1000 docs: 0.0360
R-Precision (precision after R (= num_rel for a query) docs retrieved):
Exact: 0.4889
I ran the language model with Jelinek-Mercer smoothing "401. foreign minorities, germany" for the WT2g collection (with stemming), without doing any fancy query processing (just word tokenization). Below you can find some of the statistics I got back by running trec-eval on the results for this query:
Queryid (Num): 401
Total number of documents over all queries
Retrieved: 1000
Relevant: 45
Rel_ret: 36
Interpolated Recall - Precision Averages:
at 0.00 0.1429
at 0.10 0.0633
at 0.20 0.0486
at 0.30 0.0459
at 0.40 0.0438
at 0.50 0.0433
at 0.60 0.0396
at 0.70 0.0396
at 0.80 0.0396
at 0.90 0.0000
at 1.00 0.0000
Average precision (non-interpolated) for all rel docs(averaged over queries)
0.0407
Precision:
At 5 docs: 0.0000
At 10 docs: 0.0000
At 15 docs: 0.1333
At 20 docs: 0.1000
At 30 docs: 0.0667
At 100 docs: 0.0500
At 200 docs: 0.0400
At 500 docs: 0.0400
At 1000 docs: 0.0360
R-Precision (precision after R (= num_rel for a query) docs retrieved):
Exact: 0.0889
If your system is dramatically under-performing that, you probably have a bug.
What to hand in
Provide a short description of what you did and some analysis of what you learned.
You should include at least the following information:
- Un-interpolated mean average precision numbers for all 8 runs.
- Precision at rank 10 documents for all 8 runs.
- An analysis of the advantages or disadvantages of stemming, IDF,
and the different smoothing techniques.
Feel free to try other runs to better explore issues like the last on mentioned
above, e.g. how does Okapi tf compares to raw tf, what impact do different values
of lamba have on smoothing, etc.
Hand in a printed copy of the report. The report should not be much longer
than a dozen pages (if that long). In particular, do not include trec_eval
output directly; instead, select the interesting information and put it in a
nicely formatted table.
Grading
This project is worth 250 points. To get about 200 points, you need to do the
things described above.
Additional points will be awarded for doing things such as:
- Extra runs, particularly interesting runs that do more than vary
parameters (up to 15 points).
- Recall/precision graphs, per query or more interestingly averaged over
all queries (up to 15 points).
- Analysis beyond the minimum required (up to 20 points). A good
analysis should investigates interesting phenomena in details. For instance,
failure analysis per query, i.e. looking at the query-by-query performance and
explore what makes some queries fail, etc.
Switch to:
ekanou@ccs.neu.edu