To learn about a commonly used data structure, the hash table. To examine the hash table's performance under many conditions and to see in what cases it should be utilized, and in which it should be avoided.
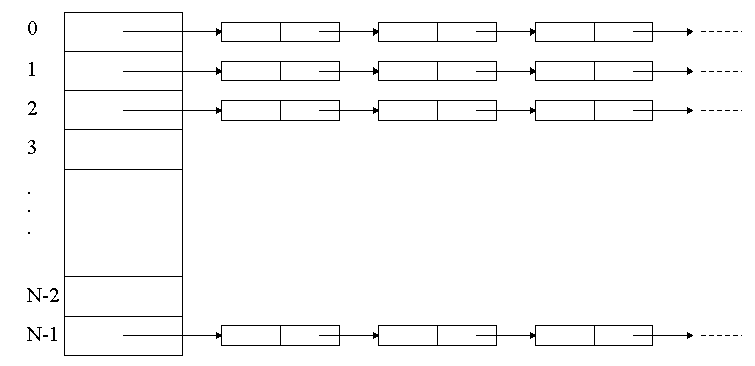
What is a hash table? Basically you can think of it as a data structure that is organized in a similar manner to a dictionary. Professor Proulx has made an example of searching through a dictionary by opening it up to the middle, deciding whether your word is greater or less than the words on the current page, then splitting that half in half. But this isn't really how it works. On the outside of the dictionary are a set of markings telling which letter the pages in that part of the dictionary start with. When we are looking for a particular word, we can open up the dictionary to the section corresponding to the first letter in the word. By making this choice, we only have to search around 4% of the dictionary to find the word we are looking for in theory.
Pretty sweet huh? Well, maybe, it depends on our hash function. In the example of the dictionary, the hash function was to take the first letter of the word we wanted to look up and categorize by that. This leads to an inbalance between the letters. You can be sure that x has far less entries than s. Well, the same can happen with our hash tables. What if we choose to store information about all of the Christmas celebrations over the past 2003 years (since obviously there couldn't be any celebrations before that, now could there?) and we decide to hash the values by the day of the month on which the celebration fell. All celebrations that fall on the same day are put into the same "bucket." A bucket is just a linear data structure that our hash uses to store values that hash to the same location. Stupid hash, huh? Our grand hash table has now resorted into a nearly linear structure since most Christmas parties will be within a few days of Christmas. The hard part of a hash table isn't really understanding how it works, it's determining an appropriate hash function that will divide up your data well. Fortunately a good amount of work has been done to provide these functions for common datatypes (such as Strings) which allows us to just utilize it and move on.
Now we want to implement some thing (.zip or .exe)using Java's HashMap class. We're going to be working on a Ciy class which will include a name, state, and a population. These are the values we will be hashing, and we will also be iterating through a group of Zipcode structures which include City information as well as a population and zip. Notice there may be multiple ZipCode entries for a single City. Implement the framework for reading in the ZipCodes from a file, one by one, and then checking if the City is in the hash table. If it is, increment its population by the correct amount and put it back in the hash table. If it is not, add it into the hash table with the population set at the one given.
Try doing this with a couple different hashing functions. In order to do this, you need to modify the equals and hashCode functions as defined in Java Object. Try a few different types, first just use 0, then try using the hash of just the state name, finally, try adding the hash of the state name and the city name. See how the performance differs in all these cases.