A. The following list of R's and N's represents relevant (R) and non-relevant (N) documents in a ranked list of 50 documents. The top of the ranked list is on the left of the list, so that represents the most highly weighted document, the one that the system believes is most likely to be relevant. The list runs across the page to the right. This list shows 10 relevant documents. Assume that there are only 10 relevant documents for this query.
RRNRNRNNNN RNNNRNNNNR RNNNNNNNRN NNNNNNNNNN RNNNNNNNNN
Based on that list, calculate the following measures:
1. Average precision
2. Inerpoloated precision at 50% recall
3. Interpolated precision at 33% recall
4. R-precision
B. Now, Imagine another system retrieves the following ranked list for the same query.
RNNRNNNRNN NNNRNNNNNN NRNNNNNNRN NNRNNNNRNN NNNNRNNNNR
Repeat parts (A.1), (A.2), (A.3), and (A.4) for the above ranked list. Compare the two ranked lists on the basis of these four metrics that you have computed--i.e., if you were given only these four numbers (Mean Average Precision, Precision at 50% recall, Precision at 33% recall, and R-precision) what can you determine about the relative performance of the two systems in general.
C. Plot a recall/precision graph for the above two systems. Generate both an uninter-polated and an interpolated graph (probably as two graphs to make the four plots easier to see). What do the graphs tell you about the system in A and the one in B?
D. Plot ROC curves for the above two systems.
Problem 3 (15 points)
Let 'perfect-retrieval' be defined as a list of ranked documents where
- all the relevant documents are retrieved and
- every relevant document is ranked higher than any non-relevant one.
A. Prove that at a list demonstrates perfect-retrieval if and only if there exists a cutoff=c such that the list has PREC(c)=1 and RECALL(c)=1
B. Consider a particular cutoff c=10
B1. Give example of a list that has PREC(10)=1 and RECALL(10)<1
B2. Give example of a list that has PREC(10)<1 and RECALL(10)=1
C. Prove that a list demonstrates perfect-retrieval if and only if R_PREC=1
D. Prove that a list demonstrates perfect-retrieval if and only if AveragePrecision=1
Problem 4 (15 points)
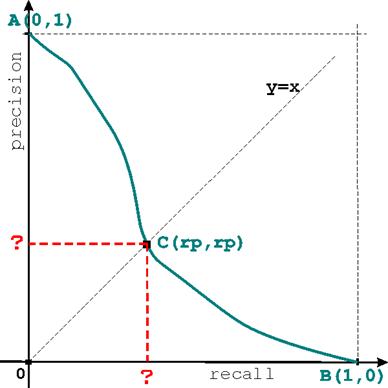 Consider a typical precision-recall curve
starting at A (RECALL=0,PREC=1) and
ending at B(RECALL=1,PREC=0)as shown
in the plot (1) below.
Consider a typical precision-recall curve
starting at A (RECALL=0,PREC=1) and
ending at B(RECALL=1,PREC=0)as shown
in the plot (1) below.
A. Every point on the precision-recall curve corresponds to a particular rank (or cutoff). Intersect the curve with the main diagonal given by the equation y=x at point C (rp,rp). If the query in question has R relevant documents, at what rank does this intersection point corresponds to?
B. As a consequence of the above, the quantity rp represents a standard retrieval metric. Explain which one and why.
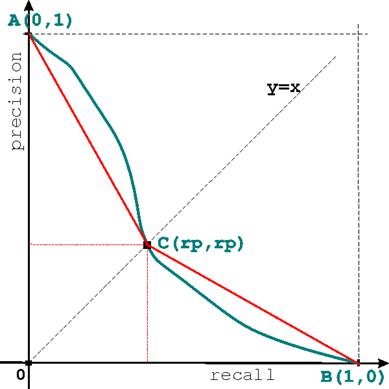
C. As shown in plot (2), we now add the segments [AC] and [CB]. We are interested in the area under the blue precision-recall curve and we can approximate it by the area under the red lines ACB. Compute this approximation area as a function of rp.
D. Explain how the average precision and R-precision measures are thus related.
Problem 5 (10 points)
Courtesy Huahai Yang
Which of the documents in Table 1 will be retrieved given the Boolean query below?
((chaucer OR milton) AND (NOT swift)) OR ((NOT chaucer) AND (swift OR shakespeare))
Table 1 Term-document weight in Boolean model
|
Chaucer |
Milton |
Shakespeare |
Swift |
D1 |
0 |
0 |
0 |
0 |
D2 |
0 |
0 |
0 |
1 |
D3 |
0 |
0 |
1 |
0 |
D4 |
0 |
0 |
1 |
1 |
D5 |
0 |
1 |
0 |
0 |
D6 |
0 |
1 |
0 |
1 |
D7 |
0 |
1 |
1 |
0 |
D8 |
0 |
1 |
1 |
1 |
D9 |
1 |
0 |
0 |
0 |
D10 |
1 |
0 |
0 |
1 |
D11 |
1 |
0 |
1 |
0 |
D12 |
1 |
0 |
1 |
1 |
D13 |
1 |
1 |
0 |
0 |
D14 |
1 |
1 |
0 |
1 |
D15 |
1 |
1 |
1 |
0 |
D16 |
1 |
1 |
1 |
1 |
Problem 6 (10 points)
Courtesy Huahai Yang
Given a query Q and a collection of documents A, B and C shown in Table 2, rank the similarity of A, B, and C with respect to Q using the cosine similarity metric.
The numbers in the table are the (e.g., tf-idf) weights between each term and document or query; simply compute the cosine similarity using these weights.
Table 2 Term-Document Weights
|
Cat |
Food |
Fancy |
Q |
3 |
4 |
1 |
A |
2 |
1 |
0 |
B |
1 |
3 |
1 |
C |
0 |
2 |
2 |
jaa@ccs.neu.edu