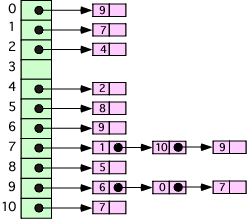
Question 1. Assume that initially, the id array for the Quick-Find algorithm has the entries shown.
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| id[i] | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
1.A Show the appearance of the array (just the lower, id[i] part) after each of the following pairs is inserted:
3,4 7,2 4,9 1,2 8,5
1.A -- ANSWER The idea here is to show the array with the id values after each integer pair is processed. The code below shows that when the id is reset, it is set to the id of the second item in the pair ( id[i] = id[q] ).
| p,q | i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 3,4 | id[i] | 0 | 1 | 2 | 4 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 7,2 | id[i] | 0 | 1 | 2 | 4 | 4 | 5 | 6 | 2 | 8 | 9 | |
| 4,9 | id[i] | 0 | 1 | 2 | 9 | 9 | 5 | 6 | 2 | 8 | 9 | |
| 1,2 | id[i] | 0 | 2 | 2 | 9 | 9 | 5 | 6 | 2 | 8 | 9 | |
| 8,5 | id[i] | 0 | 2 | 2 | 9 | 9 | 5 | 6 | 2 | 5 | 9 |
Perhaps the most interesting case above is when the 4,9 is inserted, because at this point every item with the id of 4 (which is 4) is changed to the id of 9 (which is 9). Since item 3 has the id of 4 it is also changed to 9.
1.B List the sets of values that have been created after the five insertions are finished. Use the standard set notation, i.e., a set made up of 3, 37 and 14 would be denoted by {3,37,14}.
1.B -- ANSWER Looking at the final row of the array above, we see that one item is in the set labeled by id=0, so this is a set {0}. Three items are in the set labeled by 2, which gives the set {1,2,7}. The sets {3,4,9}, {6} and {8,5} are also present, so the final list is {0}, {1,2,7}, {3,4,9}, {5,8}, and {6}.
Question 1 -- General discussion -- ANSWER One way to view these union operations that are done in both Quick-Find and Quick-Union, is to take an example such as the following: Suppose each number represents a music store. Every pair, such as 3,4 represents the statement "is in the same city as". Thus if we enter 3,4, the algorithm couples them together -- those two stores are in the same city. Later, if we enter 4,9, this means that store 4 and 9 are in the same city. But since 3 and 4 are also in the same city, 3 and 9 must be also. We represent these by a set {3,4,9} -- these three stores are in the same city. The same argument applies when we enter 7,2 and later, 1,2. That means these three stores are in the same city as one another and can be described by the set {1,2,7}. (Note that this is the same set as {7,1,2}. The order doesn't matter.)
In mathematical terms we say that the relation "in the same city as" is an equivalence relation. An equivalence relation has three properties: It is reflexive -- A is in the same city as A. It is transitive, if A is in the same city as B and B is in the same city as C, then A is in the same city as C. And finally, an equivalence relation is also reflexive, so that if A is in the same city as B, then B is in the same city as A. A relation such as "<" is not an equivalence relation, since it is neither reflexive or symmetric.
An equivalence relation, applied to a collection of objects divides them into disjoint (non-overlapping) sets. This is because two objects are either equivalent or they are not -- there's no middle ground. Such a division of a collection into disjoint sets is called a partition, the partition induced by the equivalence relation.
Thought you might be interested.
***************************************
For reference, here is the Quick-Find code from Sedgewick:
int main()
{ int i, p, q, id[N];
for (i = 0; i < N; i++) id[i] = i;
while (cin >> p >> q)
{ int t = id[p];
if (t == id[q]) continue;
for (i = 0; i < N; i++)
if (id[i] == t) id[i] = id[q];
cout << " " << p << " " << q << endl;
}
}
Question 2. For estimating the complexity of binary search and sequential search, you only need to think about finding a name in a phone book vs. finding a name in an unsorted list of names. In 2.A and 2.B below, state the Best Case and the Worst Case complexities in "Big Oh" notation, assuming there are N items to be searched. In each case, of course, describe how you arrived at your answers.
2.A Write down your estimates for binary search.
2.A -- ANSWER We can imagine that we are looking in a phone book with N=1024=210 pages. It takes at most ten steps to find any item, each one cutting the number of pages in half. This is the worst case. The search can never require more than that number of steps. This number is lg1024=lg210=10. In general, the complexity of the search, in the worst case, is therefore O(lgN). In the best case, you find the item you are looking for on the first page you look at when you divide book in half. This is a one-step process, independent of the value of N, so it is O(1), or constant time complexity. Note that it makes no sense whatsoever to conduct a binary search on a collection of items that are not sorted, in order.
2.B Write down your estimates for sequential search.
2.B -- ANSWER Sequential search is what you are forced to use when the collection of items is not in any order. To find an item an algorithm will have to examine every item in the collection until the item is found, or go to the end of the collection if it is not found. If the number of items is doubled, the time it takes to do this is doubled. This means that the complexity is O(N). The best case is similar to that for binary search -- the first item you look at could be the one you're looking for, leading to a O(1) or a constant time best case.
2.C Extra Credit: What are the average complexities for the two searches?
2.C -- ANSWER For binary search, the analysis is not trivial. If the item is present in the collection being searched, then on average there is a 1/N chance that the search will terminate on the first step, a 2/N chance it will terminate on the second, etc. This leads to a reduction of about one step for the entire search, on the average. So the number of steps is approximately (lgN) - 1. The most important point about this is that the Big Oh complexity is unchanged by subtracting a constant from lgN. When N is sufficiently large, this still behaves like lgN so the complexity is still O(lgN). All this assumes that the item is found. If the item searched for is not in the collection, even the slight saving is not made, since the binary search will be run to termination. Again, O(lgN).
The average case for sequential search also depends on whether the item is present or not. If it is, then on average, N/2 steps are required to find it. If not, N steps are required. Both N/2 and N are O(N), properly expressed in Big Oh notation. You should never write "O(N/2)". That is incorrect notation.
Question 2 General discussion -- ANSWER Though both of the best cases here are O(1), that is certainly not the case in general. For example, the best case for the improved insertion sort is when the array is already sorted. In this case, the algorithm still has to scan from right to left to position the smallest element, N steps. Then it has to move through the array from left to right and at each position the inner ("while") loop will fail, so it still must examine N elements as it moves to the right. The total number of items it examines in the two scans is 2N, so the complexity is O(N).
There was a lot of confusion in the answers to this question. What people wrote and what they stated in Big Oh notation were often quite different. People wrote in general terms such as "it would take many, many steps" instead of thinking through how many steps would be involved for a collection of N values.
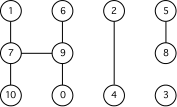
Question 3. The figure below is the adjacency-list representation of a graph.
Draw the graph corresponding to the adjacency list. (Hints: The graph has four separate components that are not connected with one another. Laid out properly on the page, they look like H I ! )
|
|
|
3. -- ANSWER The graph to the right shows one correct answer to the problem. Any other answers in which the nodes have the same connections as above is also correct. Their exact layout in space is not crucial. Most people did well on this problem.
Question 4. Assume that the array shown below is in the
process of being sorted by the insertion sort
function shown below it. Assume that the for loop body is beginning to execute with
i = 7. Show the successive changes in the a[] array until this i = 7
execution of the for loop body is finished.
That is, until its a[j] = v; statement has executed.
4. -- ANSWER The table below shows how the assignments a[j] = a[j-1] are done, moving items to the right until the test v < a[j-1] fails at j=2 because v=5 is not less than a[2-1]=a[1]=4. Notice that there is no swapping (interchange) of elements, only "moves to the right". The value 5 is never assigned to any of the intervening positions in the array. It is simply assigned to the v variable and held there until it is finally placed in its correct position. Many people thought that the 5 was moved to the left one position at a time, being swapped as it went. But look at the code -- no swapping is shown in the code, only values being shifted to the right.
| k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| a[k] | 1 | 4 | 7 | 12 | 20 | 24 | 31 | 5 | 2 | 50 | |
| j=7 | 1 | 4 | 7 | 12 | 20 | 24 | 31 | 31 | 2 | 50 | |
| j=6 | 1 | 4 | 7 | 12 | 20 | 24 | 24 | 31 | 2 | 50 | |
| j=5 | 1 | 4 | 7 | 12 | 20 | 20 | 24 | 31 | 2 | 50 | |
| j=4 | 1 | 4 | 7 | 12 | 12 | 20 | 24 | 31 | 2 | 50 | |
| j=3 | 1 | 4 | 7 | 7 | 12 | 20 | 24 | 31 | 2 | 50 | |
| j=2 | 1 | 4 | 7 | 7 | 12 | 20 | 24 | 31 | 2 | 50 |
After the while terminates at j=2, a[2] is assigned the value v=5:
| j=3 | 1 | 4 | 5 | 7 | 12 | 20 | 24 | 31 | 2 | 50 |
void insertion(int a[])
{ int i;
for (i = N; i > l; i--) compexch(a[i-1], a[i]);
for (i = 2; i <= N; i++)
{ int j = i; int v = a[i];
while (v < a[j-1])
{ a[j] = a[j-1]; j--; }
a[j] = v;
}
}
Question 5.A. Using a set of increasing N's, each a power of 2, show which term in the following CN expression below eventually dominates numerically, and therefore, what the "Big Oh" complexity of the expression is.
CN = 16*N + NlgN
5.A. -- ANSWER There are various ways to approach this problem. The simplest is to notice that 16*N starts out larger than NlgN and ask if there is some value of N for which NlgN "catches up" and is equal to 16*N. To start out with, for N=2, the two terms are 16*2=32 and 2lg2=1. If we equate the two terms, 16*N=NlgN and simplify this by dividing by N to get 16=lgN, we can see that it has a solution -- the value of N for which lgN=16 is simply N=216. So even though 16*N starts out smaller, by the time N gets to 216, the two terms are equal.
What happens for much larger N? Let's try N=21000. For this value, 16*N=16*21000 but NlgN=1000*21000. So for this huge value of N, the second term is 1000/16 times larger, about 60 times larger.
The conclusion? The conclusion is that the term NlgN eventually dominates and the 16*N term becomes a negligible fraction of the CN sum as N gets very large. We describe this by saying that the expression CN = 16*N + NlgN is O(NlgN).
5.B Optional Extra Credit: Solve the recurrence relation
CN = CN/2 + 1
for N5.B. -- ANSWER This is exactly the example of Formula 2.4 in Sedgewick, pg. 51. For N=2n, the recursion reduces after n steps to CN/2=n or CN/2=lgN. This describes the familiar operation of binary search discussed in Question 2A of this quiz.